
kubernetes核心技术-Pod

kubernetes核心技术-Pod
墨颜丶初识 Pod:Kubernetes 的最小运行单元
Pod 是什么?
在 Kubernetes(K8s)的世界中,Pod 是最小的可部署和管理单元。它不仅是容器的“家”,更是 Kubernetes 资源对象模型的核心。无论是部署应用、管理网络,还是配置存储,所有操作最终都会通过 Pod 来实现。
Pod 的核心特性
- 资源共享:
Pod 内的多个容器可共享网络(对外同一IP和端口空间)和存储卷。例如亲密性应用,一个 Tomcat 容器和一个 Redis 容器可以共享数据卷,实现高效通信。 - 生命周期短暂:
Pod 可能因节点故障被重新调度到其他节点,但新 Pod 与旧 Pod 完全无关。因此,状态数据必须存储在外部(如持久卷)。 - 平坦网络:
所有 Pod 处于同一共享网络空间,可通过IP直接访问,无需额外配置。
Pod 的内部结构:Pause 容器与多容器协作

Pause 容器:Pod 的“守护者”
每个 Pod 都包含一个由 Kubernetes 自动创建的Pause 容器,它是 Pod 的“根容器”。其作用是:
- 共享资源:为其他容器提供网络和存储的共享基础。
- 生命周期管理:通过管理 Pause 容器,Kubernetes 可以统一控制 Pod 中所有容器的启动、停止和重启。
多容器 Pod 的协作场景
| 模式 | 场景案例 | YAML 配置要点 |
|---|---|---|
| Sidecar | 主容器(Nginx) + Sidecar容器(日志收集)共享日志卷 | volumeMounts + emptyDir |
| Adapter | 主容器(MySQL) + Adapter容器(配置文件热加载) | configMap 挂载 + 文件监听脚本 |
示例:Sidecar模式实战
1 | apiVersion: v1 # 指定 Kubernetes API 的版本(v1 是核心 API 组)。 |
Pod 的生命周期:从创建到销毁
Pod 的状态解析
| 状态值 | 说明 | 典型场景 |
|---|---|---|
| Pending | Pod 已创建,但容器镜像尚未下载或初始化 | 首次部署时等待镜像拉取 |
| Running | 所有容器已创建,至少有一个容器处于运行、启动或重启状态 | 正常提供服务 |
| Completed | 所有容器成功退出且不再重启(常见于 Job 或批处理任务) | CronJob 完成数据处理 |
| Failed | 容器退出失败(非零退出码),且无法自动恢复 | 应用启动时依赖服务不可用 |
| Unknown | 因网络问题无法获取状态(如节点与 API 服务器通信中断) | 节点网络故障 |
Pod 重启策略
Kubernetes 提供三种重启策略,直接影响 Pod 的行为:
| 策略 | 行为 | 适用场景 |
|---|---|---|
| Always | 容器崩溃或退出时,强制重启(默认策略,适合长期运行的服务)。 | 核心服务(如 Web 服务器) |
| OnFailure | 仅当容器退出码非零时重启(适合需要恢复的任务)。 | 任务型作业(如数据迁移) |
| Never | 从不重启容器(适合一次性任务,如数据迁移)。 | 一次性调试任务 |
策略对比表
| 容器数 | 事件 | Always | OnFailure | Never |
|---|---|---|---|---|
| 单容器 | 成功退出 | 重启 → Running | 完成 → Succeeded | 完成 → Succeeded |
| 单容器 | 失败退出(非零码) | 重启 → Running | 重启 → Running | 不重启 → Failed |
| 双容器 | 1 容器失败退出 | 重启失败容器 → Running | 重启失败容器 → Running | 不重启 → Running |
示例:
- 使用
OnFailure策略的 Job 容器,若因代码错误退出码为1,Kubernetes 会自动重启;若正常退出码0,则标记为Completed。
Pod 的实战配置:从 YAML 到部署
Pod 的 YAML 定义核心
1 | apiVersion: v1 # API版本 |
关键配置解析
- 资源配额:
requests是容器启动的最小资源保证,limits是最大使用上限。例如:
1 | resources: |
- 镜像拉取策略:
Always:每次启动都拉取最新镜像(适合开发环境)。IfNotPresent:仅当本地无镜像时拉取(默认,适合生产环境)。Never:完全依赖本地镜像(慎用,可能导致版本不一致)。
Pod实战:创建与管理
单容器Pod示例
1 | apiVersion: v1 |
多容器Pod示例(Sidecar模式)
1 | apiVersion: v1 |
常用命令
1 | # 创建Pod |
Pod 健康检查:应用自愈的智能守卫
为什么需要健康检查?
当Java应用发生内存溢出时,进程可能仍在运行,但已无法提供服务。健康检查通过应用层探针,精准识别此类“僵尸状态”,触发容器自愈。以下深度解析K8s的探针机制与实战配置。
探针类型与行为
探针类型定义了 健康检查的用途和行为,共有三种:
| 探针类型 | 作用 | 失败后果 | 适用场景 |
|---|---|---|---|
| livenessProbe | 检查容器是否处于正常运行状态,确保容器存活。 | 触发容器重启(根据 Pod 的 restartPolicy)。 | 检测死锁、内存泄漏、长期无响应等。 |
| readinessProbe | 检查容器是否准备好接收流量,确保服务可用。 | 将 Pod 从 Service 的流量路由中剔除,但不会重启容器。 | 应用启动需要初始化时间(如依赖数据库连接、加载配置)。 |
| startupProbe | 在容器启动阶段检查应用是否成功启动,优先级高于其他探针。 | 直接终止 Pod 并触发重启(无需等待其他探针)。 | 应用启动时间长(如数据库迁移、复杂初始化流程)。 |
探针方法与参数
探针方法定义了 如何执行健康检查的具体方式,共有三种:
| 方法 | 实现方式 | 成功条件 | 适用场景 |
|---|---|---|---|
| httpGet | 向容器的特定端口发送 HTTP GET 请求。 | HTTP 状态码在 200-399 之间。 | Web 应用(如检查 /health 或 /ready 端点)。 |
| exec | 在容器内部执行 Shell 命令或脚本。 | 命令返回状态码 0。 | 检查数据库连接、配置文件、自定义逻辑(如 curl、mysql 命令)。 |
| tcpSocket | 尝试与容器的指定端口建立 TCP 连接。 | 能成功建立 TCP 连接。 | 检查服务是否监听端口(如数据库、RPC 服务)。 |
关键参数说明
所有探针(无论类型和方法)都支持以下参数:
| 参数 | 作用 | 最佳实践 |
|---|---|---|
initialDelaySeconds | 容器启动后等待多久开始首次检查。 | ≥ 应用启动时间的 1.5 倍(避免误判)。 |
periodSeconds | 检查间隔(单位:秒)。 | 5-30 秒(根据业务响应速度调整)。 |
timeoutSeconds | 单次检查超时时间。 | ≤ periodSeconds 的 1/2(避免阻塞)。 |
failureThreshold | 连续失败次数达到阈值后触发后果。 | 3-5 次(避免偶发网络波动误判)。 |
successThreshold | 连续成功次数达到阈值后恢复状态(仅 readinessProbe 需要)。 | 默认 1,但高敏感场景可设为 2-3。 |
- 优先级顺序:
startupProbe>livenessProbe>readinessProbe- 若配置了
startupProbe,其他探针在启动阶段会被禁用,直到startupProbe成功。
- 参数冲突:
initialDelaySeconds需合理设置,避免与应用启动时间冲突。failureThreshold需结合periodSeconds计算总超时时间(如15 + 5×29 = 160 秒)。
- 方法选择:
- HTTP 服务 →
httpGet - 无 HTTP 接口 →
exec或tcpSocket - 启动阶段 →
tcpSocket或exec(避免阻塞启动流程)。
- HTTP 服务 →
Probe 三种探针类型详解
livenessProbe(存活检查)
- 定义:
livenessProbe用于检查容器是否处于正常运行状态。 - 作用:如果
livenessProbe检查失败,Kubernetes会杀死该容器,并根据Pod的重启策略来决定是否重启容器。 - 示例场景:
- 如果一个应用在处理请求时崩溃或进入无限循环,
livenessProbe可以检测到这种异常并触发容器重启。
- 如果一个应用在处理请求时崩溃或进入无限循环,
readinessProbe(就绪检查)
- 定义:
readinessProbe用于检查容器是否准备好接收流量。 - 作用:如果
readinessProbe检查失败,Kubernetes会将该Pod从服务(Service)的端点列表中剔除,确保流量不会被路由到未准备好的Pod。 - 示例场景:
- 在应用启动时,可能需要一些时间来初始化数据库连接或其他外部依赖。在这段时间内,应用可能无法正确处理请求。通过配置
readinessProbe,可以确保只有当应用完全准备好时才会接收流量。
- 在应用启动时,可能需要一些时间来初始化数据库连接或其他外部依赖。在这段时间内,应用可能无法正确处理请求。通过配置
startupProbe(启动检查)
- 定义:
startupProbe是 Kubernetes 1.20 版本引入的探针,专门用于检查容器在启动阶段是否成功完成初始化。 - 作用:
- 在容器启动初期进行健康检查,若检查失败,Kubernetes 直接终止 Pod 并触发重启(无需等待其他探针)。
- 优先级高于
livenessProbe和readinessProbe,在startupProbe完成前,其他探针会被暂时忽略,避免因启动阶段的短暂异常触发误判。
- 示例场景:
- 应用在启动时需要加载大量数据或完成复杂初始化(如数据库迁移、缓存预热),此时可能会因初始化耗时较长导致
livenessProbe误判为不健康。通过配置startupProbe,可以确保初始化完成后才进入正常监控阶段。
- 应用在启动时需要加载大量数据或完成复杂初始化(如数据库迁移、缓存预热),此时可能会因初始化耗时较长导致
配置示例
以下是一个简单的YAML配置示例,展示了如何设置livenessProbe和readinessProbe:
1 | apiVersion: v1 # Kubernetes API版本,此处为v1核心API组 |
startupProbe失败时直接终止 PodlivenessProbe触发容器重启readinessProbe控制流量隔离
配置逻辑图解
graph LR
A[容器启动] --> B[startupProbe检查 .]
B -->|失败30次 .| C[终止Pod .]
B -->|成功| D[livenessProbe + readinessProbe接管 .]
D --> E{检查结果}
E -->|liveness失败 .| F[重启容器]
E -->|readiness失败 .| G[隔离流量]
Probe 三种探针方法详解
Kubernetes提供三种探针检测方式,适应不同场景需求:
httpGet
- 用途:通过HTTP GET请求检查容器的健康状态。
- 成功条件:如果HTTP响应的状态码在200-400范围内,则认为容器健康。
- 适用场景:Web服务、RESTful API
- 示例场景:
- 检查Web应用是否能够响应特定路径(如
/health)。
- 检查Web应用是否能够响应特定路径(如
1 | livenessProbe: |
exec
- 用途:在容器内部执行一个Shell命令来检查容器的健康状态。
- 成功条件:如果命令执行返回的状态码为0,则认为容器健康。
- 适用场景:数据库连接检测、配置文件校验
- 示例场景:
- 检查数据库连接是否正常。
1 | livenessProbe: |
tcpSocket
- 用途:尝试与容器内的某个端口建立TCP连接。
- 成功条件:如果TCP连接成功建立,则认为容器健康。
- 示例场景:
- 检查服务是否正在监听特定端口。
1 | livenessProbe: |
配置示例
以下是一个简单的YAML配置示例,展示了如何设置这三种类型的Probe:
1 | apiVersion: v1 |
总结
- httpGet:适用于Web应用,通过HTTP请求检查健康状态。
- exec:适用于需要执行命令的应用,如数据库连接检查。
- tcpSocket:适用于需要监听特定端口的服务。
这些Probe机制可以帮助确保Pod在出现问题时能够及时重启或调整流量路由,从而提高应用的稳定性和可用性。
总结
| 类型 | 方法 | 核心作用 | 典型场景 |
|---|---|---|---|
livenessProbe | httpGet/exec/tcpSocket | 确保容器存活,失败重启。 | 检测死锁、无响应。 |
readinessProbe | httpGet/exec/tcpSocket | 确保容器就绪,失败隔离流量。 | 应用初始化、依赖加载。 |
startupProbe | tcpSocket/exec | 确保启动成功,失败直接重启 Pod。 | 长时间启动、复杂初始化(如数据库迁移)。 |
通过合理组合探针类型和方法,可以实现更精准的健康检查,提升 Kubernetes 应用的可靠性和稳定性。
Pod 调度策略:从创建到运行
调度流程图解
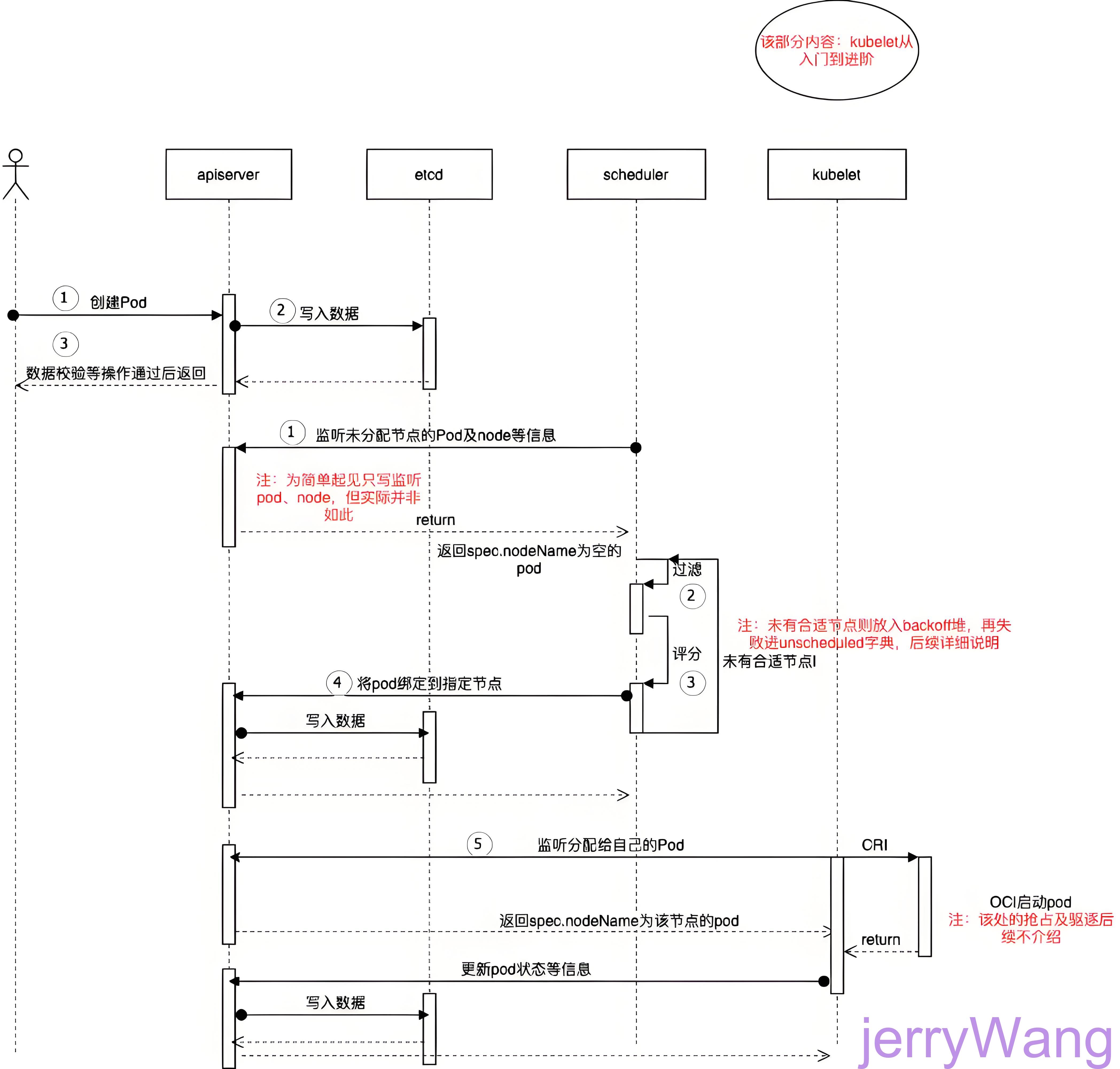
流程图解
graph TD
A[用户提交Pod请求 .] --> B[API Server验证并写入etcd .]
B --> C[Kube-scheduler监听到新Pod .]
C --> D[调度决策阶段]
D --> E{过滤阶段}
E -->|符合要求的节点| F[优选阶段]
F --> G[选择最优节点]
G --> H[Kube-scheduler绑定节点 .]
H --> I[Kubelet执行容器创建 .]
I --> J[健康检查与状态更新]
J --> K[Pod运行成功 .]
详细步骤
- 用户提交请求:
1 | kubectl apply -f pod.yaml |
API Server 验证与存储:
- 验证 YAML 格式、权限、资源配额。
- 将 Pod 信息写入 etcd。
调度器(Kube-scheduler)介入:
- 过滤阶段:筛选符合资源需求和约束的节点。
- 优选阶段:对候选节点打分,选择最优节点。
- 绑定节点:更新 Pod 的
spec.nodeName字段。
Kubelet 执行创建:
- 根据 Pod 配置拉取镜像、创建容器。
- 挂载存储(如 CSI)、配置网络(如 CNI)。
健康检查:
- 执行
livenessProbe、readinessProbe确认容器可用性。 - 更新 Pod 状态并同步到 API Server。
- 执行
调度逻辑
资源限制(Resource Limits)— 调度器的天平
核心概念
资源请求(requests):Pod向集群声明的最低资源保障,调度器根据此值选择有足够资源的节点。
1
2
3
4resources:
requests:
cpu: "500m" # 0.5核CPU
memory: "1Gi" # 1GB内存资源限制(limits):Pod允许使用的资源上限,防止资源耗尽导致节点不稳定。
1
2
3
4resources:
limits:
cpu: "2" # 最多使用2核CPU
memory: "4Gi" # 最多使用4GB内存
调度逻辑
graph TD
A[提交Pod] --> B{节点可用资源 ≥ requests? .}
B -->|是| C[调度到该节点]
B -->|否| D[跳过此节点]
C --> E[运行Pod并限制资源≤limits .]
生产实践
- 黄金比例:
limits建议为requests的2倍(突发流量缓冲) - OOM防护:必须设置内存
limits,防止单个Pod拖垮节点 - 示例配置:
1 | containers: |
节点选择器(Node Selectors)— 精准调度导航
核心机制
节点标签(Labels)
1
2# 语法
kubectl label nodes <node名称> <标签键>=<标签值>通过标签标记节点特性(如硬件类型、区域、生产环境等):
1
2
3
4
5
6
7
8# 给节点打标签
kubectl label nodes k8snode1 disktype=ssd region=us-east env_role=dev
# 查看标签
kubectl get nodes k8snode1 --show-labels
# 结果
NAME STATUS ROLES AGE VERSION LABELS
k8snode1 Ready <none> 18d v1.23.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,env_role=dev,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8snode1,kubernetes.io/os=linux,region=us-east
Pod指定目标节点
在Pod中通过nodeSelector匹配标签:
1 | spec: |
调度流程
graph LR
A[提交Pod .] --> B{节点标签匹配?}
B -->|完全匹配| C[调度到该节点]
B -->|不匹配| D[保持Pending状态 .]
高级用法
- 多标签联合筛选:
1 | nodeSelector: |
- 动态标签管理:
1 | # 实时更新标签 |
Pod 精准调度:进阶武器
节点亲和性(Node Affinity)
什么是节点亲和性?
节点亲和性是 Kubernetes 中 精细化控制 Pod 调度到特定节点 的核心机制,相比简单的 nodeSelector,它支持:
- 多条件组合:通过逻辑运算符(
In,NotIn,Exists等)定义复杂规则 - 软硬策略分离:支持必须满足的硬性条件(Required)和倾向性软条件(Preferred)
- 权重调节:为软性条件分配权重值,实现优先级调度
为什么需要节点亲和性?
典型场景
- 硬件异构集群
- GPU 节点 vs 普通节点:NVIDIA 的研究表明,在 AI 训练场景中,将计算密集型 Pod 调度到 GPU 节点可使训练效率提升 8-15 倍
- SSD 存储节点 vs HDD 节点:AWS 实测数据显示,数据库服务调度到 NVMe SSD 节点后,IOPS 提升 300%,延迟降低 70%
- 多区域部署
- 金融行业合规要求:某跨国银行采用跨区域节点亲和性策略,将交易系统 Pod 优先调度到本地可用区,减少跨区网络延迟 40ms → 2ms
- 环境隔离
- 微服务架构实践:某电商平台通过
env: prod和env: staging标签隔离生产/测试环境,避免资源争抢导致的故障率上升 17%
- 微服务架构实践:某电商平台通过
- 合规性要求
- GDPR 数据安全:某欧洲企业强制敏感服务 Pod 只能调度到 TEE(可信执行环境)节点,通过
security_level: TEE标签实现 100% 合规
- GDPR 数据安全:某欧洲企业强制敏感服务 Pod 只能调度到 TEE(可信执行环境)节点,通过
核心配置解析
- 硬性亲和性(Required)
必须满足的条件,否则 Pod 保持 Pending 状态。
1 | affinity: |
扩展说明:
operator: In→ 节点标签env_role的值必须在[prod]中operator: Exists→ 节点必须存在disktype标签(无论值是什么)- 注意事项:
nodeSelectorTerms支持多个matchExpressions,默认为 OR 关系(任意一个匹配即可)
- 软性亲和性(Preferred)
优先但不强制满足的条件,调度器根据权重(weight)选择最优节点。
1 | affinity: |
解释:
- 优先选择
region=us-east的节点(权重 80) - 次优先选择
machine-type=high-mem的节点(权重 20)
操作符大全
| Operator | 行为 | 示例 | 适用场景 |
|---|---|---|---|
In | 标签值在指定列表中 | values: [prod, staging] | 环境隔离 |
NotIn | 标签值不在指定列表中 | values: [dev] | 黑名单过滤 |
Exists | 标签键必须存在 | 无需指定 values | 必需特性 |
DoesNotExist | 标签键必须不存在 | 无需指定 values | 禁止特性 |
Gt / Lt | 标签值为数值时的比较(> 或 <) | values: ["4"](CPU核数 >4) | 资源筛选 |
注意事项:
Gt/Lt要求标签值为 字符串形式的数字(如"4"而非4)- 常见错误:直接使用整数导致匹配失败
Node Affinity 的推荐场景
| 场景 | 使用方式 | 示例 |
|---|---|---|
| 硬件异构集群 | 通过硬亲和性强制 Pod 调度到特定硬件节点(如 GPU、SSD)。 | requiredDuringScheduling:key: gpu, operator: In, values: [true] |
| 多区域/可用区部署 | 通过软亲和性优先选择同区域节点,降低跨区流量成本。 | preferredDuringScheduling:key: region, weight: 80 |
| 数据本地性要求 | 将计算任务调度到存储数据的节点,减少网络传输。 | requiredDuringScheduling:key: datacenter, operator: In |
| 环境隔离 | 强制生产环境 Pod 仅调度到 env: prod 节点。 | requiredDuringScheduling:key: env, operator: In, values: [prod] |
污点和污点容忍(Taint)
核心概念
- Taints:为节点添加标签,防止未授权 Pod 调度到该节点。
- Tolerations:Pod 需要声明容忍,才能调度到带有对应 Taint 的节点。
Taint 格式:
1 | key=value:effect |
- effect 类型:
NoSchedule:禁止调度(默认)。PreferNoSchedule:优先不调度。NoExecute:禁止调度且驱逐已有 Pod。
配置示例
为节点添加污点 Taint
1 | # 禁止未授权 Pod 调度到 k8snode1 |
Pod 声明污点容忍 Tolerations
1 | apiVersion: v1 |
扩展说明:
operator: Exists可省略 value 字段effect可省略表示容忍所有 effect 类型
典型场景
- 专用节点:如 GPU 节点:
1 | kubectl taint nodes gpu-node type=gpu:NoSchedule |
Pod 需要声明对应的 tolerations 才能调度到该节点。
- 驱逐现有 Pod:使用
NoExecute:
1 | kubectl taint nodes k8snode2 under-maintenance=true:NoExecute |
未声明 tolerations 的 Pod 将被驱逐。
Taint 的推荐场景
| 场景 | 使用方式 | 示例 |
|---|---|---|
| 专用节点隔离 | 为 GPU、数据库等专用节点添加 NoSchedule 污点,仅允许特定 Pod 调度。 | kubectl taint nodes gpu-node type=gpu:NoSchedule |
| 维护模式节点 | 在节点维护时添加 NoExecute 污点,驱逐已有 Pod。 | kubectl taint nodes node2 under-maintenance=true:NoExecute |
| 安全敏感节点 | 通过污点隔离高安全等级节点,仅允许合规 Pod 调度。 | kubectl taint nodes secure-node security=high:NoSchedule |
| 资源预留 | 为高优先级服务预留节点资源,普通 Pod 不可抢占。 | kubectl taint nodes reserved-node reserved=true:PreferNoSchedule |
综合示例:多条件调度
1 | apiVersion: v1 |
总结与推荐
| 需求类型 | 推荐机制 | 说明 |
|---|---|---|
| 强制调度到特定节点 | Node Affinity(硬) | 如 GPU 计算任务必须调度到 GPU 节点。 |
| 优先调度到优选节点 | Node Affinity(软) | 如优先选择同区域节点以减少延迟。 |
| 隔离专用资源 | Taint(NoSchedule) | 如 GPU 节点、数据库节点仅允许特定 Pod 调度。 |
| 维护或故障处理 | Taint(NoExecute) | 如节点维护时驱逐 Pod,确保服务连续性。 |
| 组合策略 | 联合使用 | 通过 affinity + tolerations 实现复杂调度逻辑(如专用节点 + 硬亲和性)。 |
通过合理组合 Node Affinity 和 Taint,可以实现 Kubernetes 集群的精细化调度,提升资源利用率、服务可靠性和运维效率。
Pod 分类与特殊场景
普通 Pod vs 静态 Pod
| 类型 | 管理方式 | 生命周期 | 适用场景 |
|---|---|---|---|
| 普通 Pod | 通过 API Server 调度(如 Deployment/StatefulSet) | 受控制器管理,故障自动恢复 | Web 应用、微服务、需要弹性伸缩的业务 |
| 静态 Pod | kubelet 直接管理(无需 API Server) | 节点重启后自动恢复,但跨节点不可调度 | 控制平面组件(如 kube-apiserver)、节点级守护进程(日志/监控 Agent) |
静态 Pod 核心特性
- 管理方式:
- 本地化管理:配置文件存储在节点本地路径(默认
/etc/kubernetes/manifests/),由 kubelet 定期扫描并维护。 - 无 API 依赖:即使 API Server 故障,静态 Pod 仍能运行,适合关键系统组件。
- 本地化管理:配置文件存储在节点本地路径(默认
- 生命周期:
- 自动重启:kubelet 检测到 Pod 异常退出时,会自动重启。
- 节点绑定:始终绑定到所在节点,无法跨节点迁移。
- 数据存储:
- 不存储到 etcd:元数据不会同步到集群中心存储,无法通过
kubectl直接管理。
- 不存储到 etcd:元数据不会同步到集群中心存储,无法通过
静态 Pod 的部署示例
场景:在节点上部署日志收集 Agent(如 Fluentd)
在节点的 /etc/kubernetes/manifests/ 目录下创建 YAML 文件:
1 | apiVersion: v1 |
- 关键点:
hostPath:直接访问节点本地文件系统,适合日志收集等场景。kube-system命名空间:Kubernetes 系统组件通常部署于此,避免与其他业务 Pod 混淆。
验证部署:
1 | kubectl get pods -n kube-system -l name=node-logger |
常见问题与最佳实践
Pod 无法启动的排查步骤
- 检查状态:
kubectl describe pod <pod-name>查看事件日志。 - 镜像问题:确认镜像名称正确且可拉取(使用
imagePullPolicy: Always测试)。 - 资源不足:节点资源(CPU/Memory)是否耗尽?
- 配置错误:检查端口冲突或存储卷挂载路径。
典型错误处理
| 现象 | 原因分析 | 解决方案 |
|---|---|---|
| OOMKilled | 内存超过 limits | 调整 limits 或优化应用内存使用 |
| Port conflict | 端口冲突 | 检查 containerPort 独特性 |
| Health check failed | 探针配置错误 | 验证探测路径/命令和超时设置 |
高性能 Pod 配置建议
- 资源预留:根据应用需求合理设置
requests和limits。 - 共享存储:使用
emptyDir或PersistentVolume实现容器间数据共享。 - 健康检查:通过
livenessProbe和readinessProbe主动监控容器状态。
总结
Pod 是 Kubernetes 的基石,理解其核心机制和配置细节,能显著提升应用的稳定性和可维护性。无论是构建微服务、批处理任务,还是节点级守护进程,合理利用 Pod 的特性都能事半功倍。掌握 Pod 的生命周期、重启策略和资源管理,是你成为 Kubernetes 高手的第一步!
延伸阅读:















